





PDFファイルから文字を抽出
メモ帳を利用した文字列の流用
いろんな原稿を書く際に、PDFファイルの文字の部分をコピーして流用できる。
WEBサイトなどをそのままコピーすると、文字列そのものは問題ないものの、罫線や文字のサイズ、装飾(例えば、フォントのタイプ、太字、色、その他)、リンクなどいろんな属性を引き継いでしまうので、ワードやエクセルに貼り付けて活用する際に不都合なことが多い。

左のページをPDFファイルにすると2ページになる。
着色部から文字抽出を試みると、右のようなメモ帳を作成することができる。
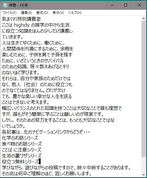
赤枠部分は特殊な入力のため、着色部を文字列として抽出した後、もう一度赤枠部分を抽出して、挿入すると、このような結果になり
ワードやエクセルで利用しやすいものをつくることができる。
オリジナル文書
PDFファイル化
文字抽出結果

画像からの文字抽出は不可能!
このように、WEB上の各サイトやPDFファイルから文字列の抽出が可能である。
しかし、画像の中にある文字列抽出は不可能である。
試しにこのHPのトップページに移動し、右上の部分で試していただくと、
よく理解できる。着色部の下の文字列は、文字をコピーするためのハイライトができるが、着色部の文字列は選択(ハイライトすること)ができない。
すなわちこの部分は、画像として入力されていることを意味する。
上の文字抽出作業をいかにビデオにしておいたので、参考にしてこの手法を活用されるといいだろう。


